A non abstract systems design for a secret store.
Preface
This is kind of a joke. I wrote the one pager and six pager a long time ago and had always been meaning to write the actual systems design. There are plenty of things wrong with this design some of which I point out in the open questions. The idea behind all of this work is to show you the amount of work that goes into going from an idea to a working concept to then implementation.
Required reading
Design
Constraints
400MM DAU.
2:1 read:write ratio.
10 reads per day per user.
5 writes per day per user.
Globally available system.
Requirements
Let’s assume an upper bound write size of 2MB. The reason for the large size relative to secret storage is that in the one pager and six pager I wrote that we need to support secret document storage.
So in that case 2MB is actually small. These documents are going to include OCR’d images in the detail of 1280 x 720 images.
Storage
DAU * Writes per user * upper bound write size
Storage = 400MM * 5 * 2MB.
So the way I work this out is scale the write size up to the same factor as the DAU.
400MM * 5 = 2 * 10^9 = 2,000,000,000
2MB * 1000 = 2GB.
2GB * 1000 = 2TB.
2TB * 1000 = 2PB.
The size of the write is now at the factor of 10^9 so we can now multiply it by 2.
2 * 2PB = 4PB of storage per day.
4PB * 31 = 124PB per month.
Large single HDD capacity is approx 16TB.
4PB of storage = 1PB / 16TB = 64 * 4 = 256 16TB disks.
Throughput
((400 * 10^6) * 5) / (8.64 * 10^4) = 24,000 reads per second.
Due to the known ratio you can just divide the writes by 2 to get the writes.
12,000 writes per second.
Looking at a DB storage requirement of 64 hosts each with 4 16TB disks attached that can sustain 12,000 writes per second across the 64 hosts. So each host needs to be able to support 190 writes per second.
Network throughput
Remember 1GB/s = 10Gb/s
24,000 * 2MB = 48,000MB = 48GB = 480Gbps = 12 50Gbps NICs to support the per second read throughput from the DB cluster.
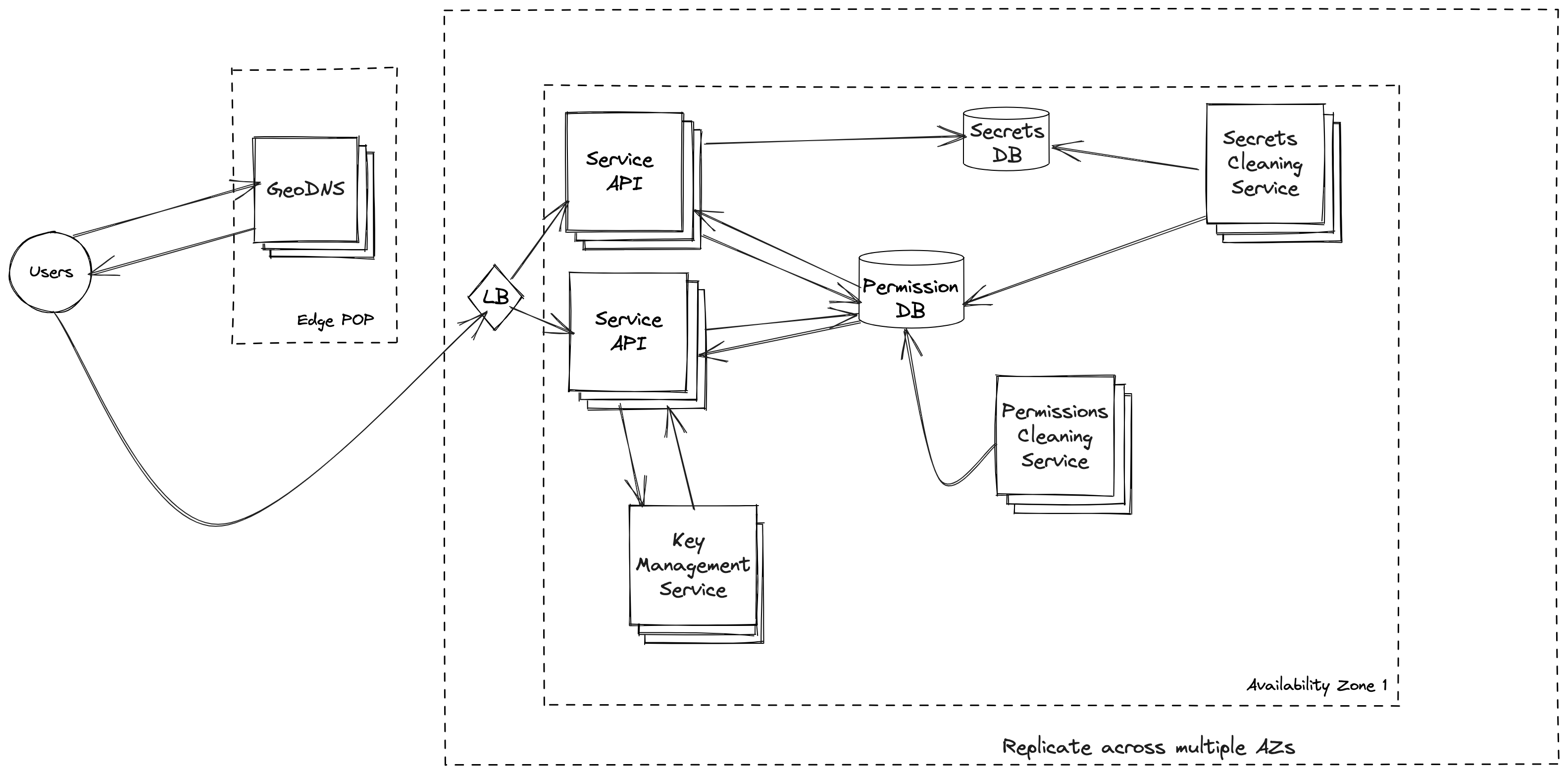
Components
Service API
Responsibility
- Middle layer between DB.
- Enforce permissions on requests.
- Encrypt secret payloads.
Technology
- Python or Go service
- gRPC
If we have to run it ourselves.
- Docker
- Kubernetes
- Vagrant
If we can use fancy cloud services.
- AWS EKS
- AWS SWF
- AWS Lambda
Key Management Service
Responsibility
- Management of encryption keys
- Entire life cycle of key data (rotation, expire)
Tech
I am assuming we can use a cloud service here as running your own KMS and encryption service is another systems design in itself.
- AWS KMS.
- AWS Encryption SDK.
Permissions DB
Responsibility
- Stores who should have access to which secret.
- Does not store secrets themselves.
Technology
If we have to run it ourselves.
- A shared Vitess DB.
If we can use fancy cloud services.
- AWS Aurora.
Schema
(secret_id, permissions)
Secret Store DB
Responsibility
- To actually store the secrets.
- So far I am not sure if metadata will be stored with the secrets or in a separate database. The idea being to keep the table design as lean as possible to keep throughput high.
Technology
If we have to run it ourselves.
- Apache Cassandra.
If we can use fancy cloud services.
- AWS DynamoDB.
Schema
(secret_id, secret_payload)
Secret Cleaning Service
Responsibility
Runs on a schedule and removes rotated secrets from the Secret Store DB. The idea being that to rotate a secret we only need to overwrite the permissions to it with a sentinel/marker value. A new secret with duplicated permissions can be created to act as the rotated secret.
This way we get the scalability of the NoSQL DB Secrets Store but atomic operations in regards to access control for the permissions with the Sharded Vitess permissions DB.
Technology
- Python or Go service
- gRPC
If we have to run it ourselves.
- Docker
- Kubernetes
- Vagrant
If we can use fancy cloud services.
- AWS EKS
- AWS EC2
- AWS SWF
- AWS Batch
Permissions cleaning service
Responsibility
Runs on a schedule and deletes old permissions. It will only remove a permission entry if the corresponding secret ID does not exist in the Secrets DB. Meaning that the Secret Cleaning Service has kicked in and done its job.
Technology
- Python or Go service
- gRPC
If we have to run it ourselves.
- Docker
- Kubernetes
- Vagrant
If we can use fancy cloud services.
- AWS EKS
- AWS EC2
- AWS SWF
- AWS Batch
Flow
Create
- User sends request to API to create a secret with a specified payload.
- The API uses the KMS to encrypt the secret and base64 the payload.
- The API stores the encrypted secret in the Secrets DB.
- The API creates a permission to secret mapping in the permission DB using the LDAP group that the user belongs to.
- The API returns the secret ID to the user.
Read
- User sends request to API with the ID of the secret they want to read.
- API checks with the permissions DB that the ID for the secret matches the permissions of the user requesting access.
- If the permissions check is good the API then retrieves the secret from the Secrets DB.
Rotate
- User sends request to API with the ID of the secret they want to rotate.
- API checks with the permissions DB that the ID for the secret matches the permissions of the user requesting access.
- If the permissions check is good. The API generates a random secret and inserts it in the Secret DB.
- The API inserts a new row in the permissions DB with the same permissions as before but mapping to the ID of the newly created secret.
- The API updates the permissions of the row containing the permissions to secret mapping of the rotated secret to be a sentinel value. This will cause permission checks to fail on reads and will allow the cleanup service to find rotated secrets to delete.
Delete
- User sends request to API with the ID of the secret they want to rotate.
- API checks with the permissions DB that the ID for the secret matches the permissions of the user requesting access.
- If the permissions check is good. The API updates the row in the permissions DB to have a sentinel value in the permissions column.
- Secret cleaning service later comes and deletes the actual secret from the Secrets DB.
Cleaning services can be interacted with via the API but will also run on a schedule to do intermittent cleanup like garbage collection.
Open questions and points
- I forgot that we are dealing with secret documents in the one pager. Storing binary blobs in a database is a terrible idea. So we are going to need block storage/object store and then store references in the database. This is why you do not design/work in a vaccum, even if it is for a joke design.
- There is currently no way for a user to list all secrets owned by them.
- There could be concurrency issues between the two cleaning services.
- There are no details on how the load balancer layer will work.
- There are no detail on how the GeoDNS will work.
- What does the CLI to interact with this service look like? does it have retries and exponential backoff?
- How are errors handled at each layer?
- How does each layer auto scale?
- What will the monitoring of this service look like?
- What metrics are we interested in?
- How do deployments work?
- How do we store backups of each database? cough put it on S3 cough
- Can we add a cache at certain layers without exposing private data or having to do more permission checks?